By Daichi Sakaue (@yokaze)
Hi, I'm Daichi, and I'm working on developing our on-premise data centers using Kubernetes (k8s). Have you ever spent a whole day rebooting all the machines in a Kubernetes cluster? Just checking the steps and chatting, a peaceful afternoon passes with a warm conversation.
Sounds nonsense? OK, let me introduce how we automate this by implementing a declarative system to gracefully reboot all servers in our Kubernetes clusters!
Background
We are running on-premise data centers for providing our services for Japanese customers. I am working in Project Neco and managing large on-premise Kubernetes clusters.
Bare-metal k8s clusters need to reboot all the servers from time to time for various reasons, such as updating firmware or fixing vulnerabilities. Since we do not want to interrupt services, the requirement is to reboot all the machines while keeping the services running.
To meet the requirement, we first tried to split the entire cluster into several machine groups and rebooted each in turn all by manual operation. However, this reboot operation became more and more difficult because many more services began running on the cluster. So we decided to implement a function in our k8s management tool CKE1 to reboot all machines.
One of the design principles of Neco is to "Be Declarative" because we want to reduce the amount of human intervention as possible. For this reason, we decided on the following specifications.
- The cluster administrator only needs to declare a single word to reboot all units. The software does all the work automatically.
- The services on the cluster will work normally even during maintenance.
- The administrator does not monitor the progress of the reboot. In case of trouble, the software automatically notifies the administrator in the form of alerts.
- The process will proceed even if a few servers fail to restart. Servers may fail to restart sometimes but their treatment can be postponed as long as the services are running healthily.
Implementation
Below are the steps to reboot all node servers:
- The administrator types
neco reboot-worker. - This command registers all servers to CKE's reboot queue. Each queue entry contains at most two servers.
- CKE periodically checks the reboot queue and reboots the servers in order if there are some waiting servers to reboot.
Neco's k8s cluster consists of two different types of servers. They are named compute and storage. These subgroups do not interfere with each other when rebooting, so we can pick up one from each and reboot them simultaneously.
The critical part is the third step, where we need to make sure that stopping all pods on the server will not affect the services before rebooting the server. Since Kubernetes has a standard feature for maintaining nodes, CKE uses this to implement the reboot of all the nodes.
How to reboot Kubernetes nodes gracefully
Kubernetes has a standard feature to safely remove pods on a node in scenarios like rebooting the node. This section explains how to use it.
PodDisruptionBudget
To restart a node participating in a k8s cluster, we need to stop all the pods on the node. Therefore, we ask the application developer to make the pods redundant and declare the number of pods removable for maintenance. PodDisruptionBudget (PDB) manages this declaration.
For example, if you create three pods as the backend of the Service and allow the cluster administrator to remove one of them, then two pods will be running even during maintenance. If you want to ensure fault-tolerance during maintenance, you need to consider the margin for this.
Pod deletion and eviction
There are two operations for removing a pod on Kubernetes: deletion and eviction.
A deletion will merely remove the pod. We can call it using kubectl delete <pod>.
An eviction will remove the pod only if it can meet the PDB after the deletion.
Eviction is usually used for node maintenance, so there is a command called kubectl drain <node> that will evict all pods on a node.
To prevent a deleted pod from being rescheduled to the same node, kubectl drain will set the Unschedulable flag on the node.
When you have finished maintaining the node, use the kubectl uncordon command to remove the flag.

In the above figure, the cluster administrator is deleting the pod on Node 1. If PDB allows the deletion of only one pod, they cannot delete any other pod on this service. Therefore, if they want to delete the pod on Node 2, they need to start a new pod on Node 1 or Node 4. Since PDB calculation only counts ready pods, they will have to wait for the new pod to have started before they delete the Node 2 pod with eviction.

How to write a PDB
Since the proper configuration of PDB varies from application to application, we need to declare it as a resource.
apiVersion: policy/v1beta1 kind: PodDisruptionBudget metadata: name: sample-pdb spec: maxUnavailable: 1 selector: matchLabels: app: sample-app
We can declare the number of redundant pods in various ways.
maxUnavailable: 1We can stop only one pod.minAvailable: 4Four or more pods should be ready.minAvailable: 80%At least 80% of the pods should be ready.
The PDB determines the number of pods to target by checking the number of replicas in the Deployment or StatefulSet specified in the pods' ownerReferences 2.
The appropriate PDB content depends mainly on whether the application is stateful or stateless.
For stateful applications, you can usually set maxUnavailable to 1 or minAvailable to the number of quorums required for a distributed consensus.
For stateless applications, you can specify an appropriate percentage depending on the load.
Please refer to the official Kubernetes documentation for details on configuring PDBs.
Eviction API
Evicting pods from nodes can be done with kubectl drain, but if you need a more fine-grained operation, you can use the Eviction API.
The Eviction API allows you to evict individual pods by specifying their names.
{ "apiVersion": "policy/v1beta1", "kind": "Eviction", "metadata": { "name": "sample-pod", "namespace": "sample-ns" } }
CKE uses the Eviction API to force application pod deletion in the development environment. Go users can call it using Evict function.
import ( policyv1beta1 "k8s.io/api/policy/v1beta1" metav1 "k8s.io/apimachinery/pkg/apis/meta/v1" ) clientset.CoreV1().Pods(namespace).Evict(context, &policyv1beta1.Eviction{ ObjectMeta: metav1.ObjectMeta{Name: name, Namespace: namespace}, })
Monitoring and alerting
We set up Prometheus metrics and alerts to know the progress of the reboot.
- We can see the number of entries in the reboot queue as a metric on Grafana.
- We raise an alert if the number of entries in the queue does not decrease for more than an hour. It usually means a PDB violation. For example, a node failed to restart may cause a StatefulSet pod to be pending. It might forbid us to evict any more pods of the StatefulSet.
- We add an alert if a node is
NotReadyfor a long time.
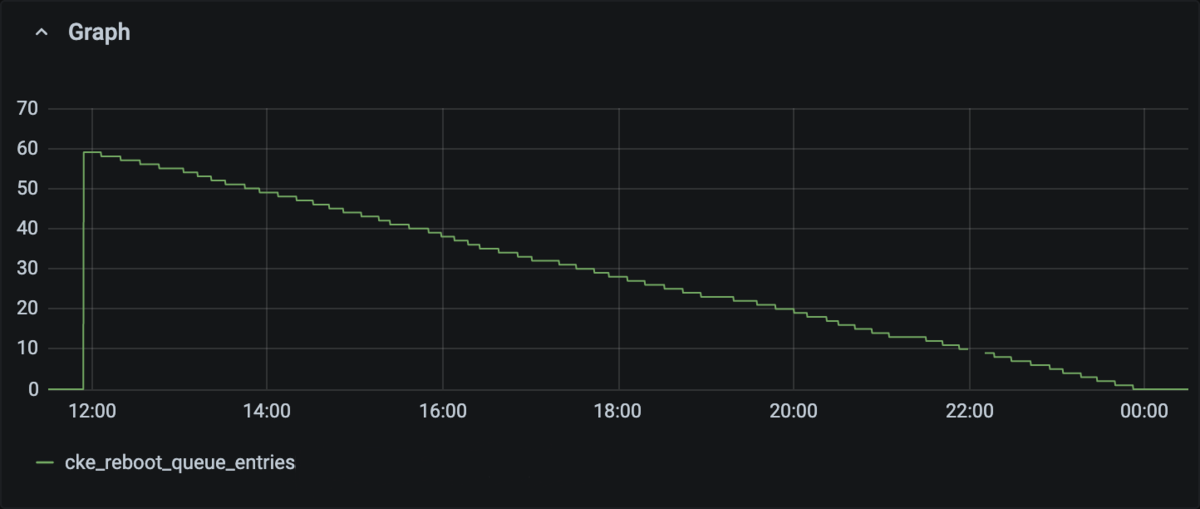
The horizontal axis of the graph represents the time, and the vertical axis represents the number of entries in the reboot queue. We can see that the process is going smoothly.
Other features
Even though it is fully automated, restarting servers sequentially at night could be a little anxious operation. Also, there may be times when you want to suspend the process when a problem occurs. For this reason, we have made it possible for the administrator to pause the queue processing by entering a command.
Conclusion
The process of rebooting all units, which used to take a day, is now done in 5 seconds by typing neco reboot-worker.
We do not need to wait for the completion of the operation, so we can immediately move on to other tasks.
We have rebooted all of our servers several times using this function, and it succeeded without any problems.
In the future, when the number of servers increases, we plan to consider rebooting on a rack-by-rack basis.
-
CKE (Cybozu Kubernetes Engine) is a certified Kubernetes software to manage k8s clusters.↩
-
https://kubernetes.io/docs/concepts/workloads/pods/disruptions/#pod-disruption-budgets↩