By Daichi Sakaue (@yokaze)
Above all the effort of the community, Kubernetes is now ready to run with cgroup v2. We recently migrated our on-premises Kubernetes clusters to use cgroup v2 and discovered some key points to know. This blog post explains what cgroup v2 is, what it brings to Kubernetes, and how to prepare for it.
TL;DR
- Configure kubelet and the container runtime in use to use the systemd cgroup driver.
- Deploy cAdvisor compatible with cgroup v2.
- Move real-time processes to the root cgroup.
- If you are using uber-go/automaxprocs, make sure it works with cgroup v2.
- Use JDK 15 or later.
Contents
- TL;DR
- Contents
- Basics
- Decide whether to adopt cgroup v2 or not
- Three things to prepare for infrastructure
- Two things to prepare for workloads
- Conclusion
- References
Basics
How Kubernetes manages requests and limits for Pods
As you all know, Kubernetes allows us to set resource requests and limits in Pod manifests. Roughly speaking, the requests fields describe the amount of resources the Pod should own, and the limits fields describe what the Pod may own. Control Group (a.k.a. cgroup) is a kernel functionality of Linux that enables these policies on a group of processes.
apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx image: nginx:latest resources: requests: memory: 128Mi cpu: 250m limits: memory: 128Mi cpu: 500m
The interface of cgroup is exposed through a virtual filesystem called cgroupfs, which is generally mounted on /sys/fs/cgroup.
It also delivers measurements of the processes' resource usage, which cAdvisor uses to collect container-related metrics.
Let's look at an example.
We have a Pod, and one of its containers has the resources.limits.memory property.
Type kubectl get pod -o wide to see in which node it resides and make an SSH connection to that node.
Then type crictl ps to see its container ID and crictl inspect to see its cgroup path.
It may appear as /sys/fs/cgroup/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf9a04ecc_1875_491b_926c_d2f64757704e.slice/cri-containerd-47e320f795efcec1ecf2001c3a09c95e3701ed87de8256837b70b10e23818251.scope.
This interface is also mounted onto the container at /sys/fs/cgroup.
It should look like this:
$ # This is an example for cgroup v2. $ # Kubernetes translates resources.limits into cgroup parameters. $ # Accessed from within a container $ cd /sys/fs/cgroup $ cat memory.max 134217728 # 128Mi $ # cgroup.procs shows what processes it contains. $ cat cgroup.procs 1 # container's main process 34 # sh 41 # cat $ # It also delivers some measurements. $ cat cpu.stat usage_usec 106492566 user_usec 66687448 system_usec 39805118 nr_periods 0 nr_throttled 0 throttled_usec 0
Before exploring cgroup v2's benefits, we need to dive a bit deeper into how the interfaces of cgroup v1 and v2 differ. As shown below, the v1 interface uses different process hierarchies for different resource types.
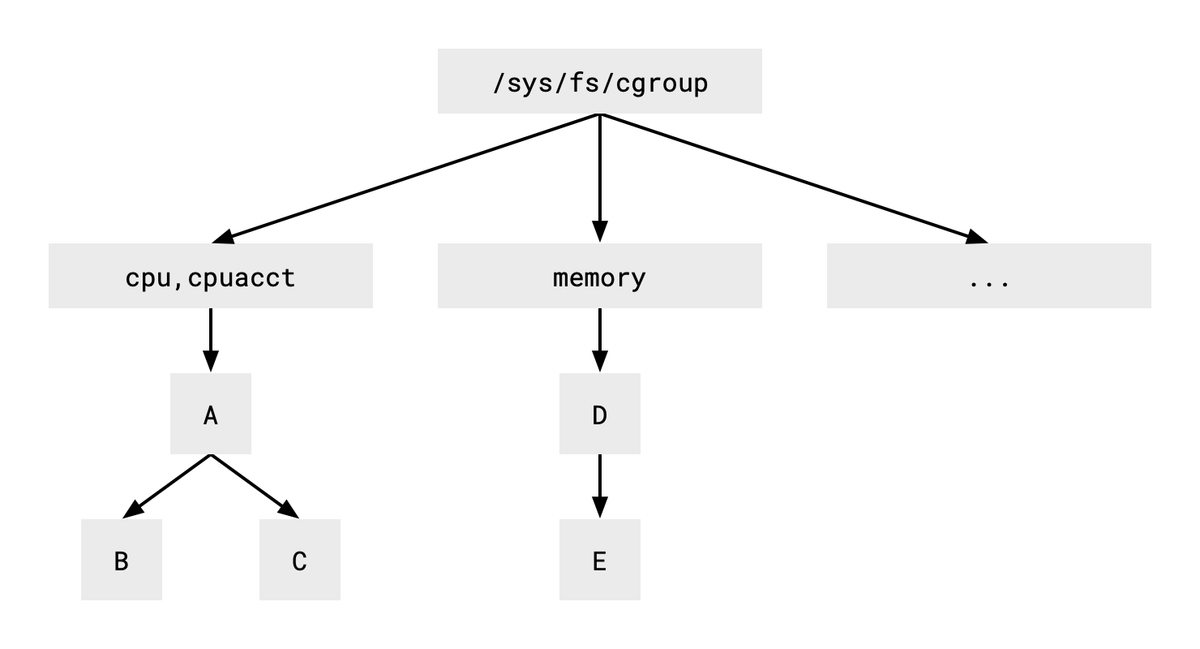
Each box in the figure represents a directory. Since the trees for CPU and memory are separate, we need to put a process into the two hierarchies simultaneously if we want to apply the consumption policies of both resource types. For example, we need to place the same process into groups B and E, allowing group B to use up to two CPU cores and group E up to 128MiB of memory.
Unfortunately, multiple hierarchies are rarely used as they incur some drawbacks with usage. The second version of cgroup uses a single unified hierarchy to solve the situation.
New features and possibilities for Kubernetes with cgroup v2
There are some additional features and expected capabilities for Kubernetes with cgroup v2. Let me introduce some of them.
One of the apparent (but not yet available) benefits of cgroup v2 is container-aware OOM killer. A container or a Pod may run multiple processes, but previously the OOM killer didn't respect their interdependency and killed only some of them. This behavior very likely leads the Pod into an inconsistent state. The cgroup v2 interface allows us to tell if the processes in a specific cgroup are interdependent and should be killed simultaneously.
Another capability is to tighten up cluster security on some use-cases. The technology to manage containers without root privilege is called Rootless Containers. It allows us to run Kubernetes node components such as kubelet by restricted users, improving security and allowing non-administrative users to create Kubernetes clusters on a shared machine.
Finally, eBPF requires cgroup v2 to enable all its functions. Cilium is an example application that extensively uses eBPF, and some of its functions require cgroup v2. For example, it can replace kube-proxy when cgroup v2 is enabled.
Ecosystem gradually moves to cgroup v2
The new version of cgroup was first released in 2016, and the ecosystem is gradually adopting it. Kubernetes v1.22 shipped with an alpha feature using cgroup v2 API. Flatcar Container Linux from v2969.0.0 uses cgroup v2 by default. We can now use cgroup v2 in production clusters.
OK, we're ready to see how to configure our Kubernetes clusters to use (or not to use) cgroup v2. Let's see the details.
Decide whether to adopt cgroup v2 or not
As cgroup v2 is one of the kernel's features, you can enable or disable it by changing the kernel's command line parameters. Please consult the upgrade guide of the Linux distribution you're using for detailed instructions. If you are using Flatcar, they provide us with a dedicated page.
If you want to postpone adopting cgroup v2, perhaps you can disable it by configuring the boot option.
Three things to prepare for infrastructure
If you decide to adopt cgroup v2, there are three things to do beforehand.
Use systemd cgroup driver
Under cgroup v2, each cgroup in the hierarchy should be managed by a single process. In most cases, systemd manages the root cgroup and creates the structured hierarchy used by the entire system. The kubelet and container runtimes should know how the system's cgroup hierarchy is organized and create their cgroups under that structure.
We can configure kubelet to follow systemd's cgroup hierarchy with:
apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd
and configure containerd with:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
Official Kubernetes documents offer us more detailed information about the cgroup driver and the configuration for other container runtimes.
After the migration, we need to check if the cgroup2 filesystem is mounted appropriately.
The following is a typical result with cgroup v2 enabled.
There should be no cgroup filesystem; that is for cgroup v1.
It is also desirable to deploy a test Pod with resources.limits set and see its values are converted to cgroup parameters.
$ mount | grep cgroup cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,seclabel) none on /run/cilium/cgroupv2 type cgroup2 (rw,relatime,seclabel)
Use appropriate cAdvisor version (Attention needed!)
Please read this section carefully if you want to use cgroup v2 now.
As mentioned above, cAdvisor collects processes' resource consumption from cgroup. We need to use an appropriate cAdvisor version because the cgroup interface changed significantly between v1 and v2. cAdvisor v0.43 supports cgroup v2, but with a minor known bug, which is fixed in v0.44, so it is desirable to use the latest version.
cAdvisor is, in many cases, served as part of kubelet; it can also be deployed as a separate DaemonSet. Therefore, we have the following options to use the appropriate cAdvisor version:
- Update Kubernetes to v1.23 because kubelet for that version embeds cAdvisor v0.43.
- Deploy the latest cAdvisor as a separate DaemonSet. It is planned to remove cAdvisor from kubelet, so this is a good enough option.
Move real-time processes to root cgroup
Unfortunately, cgroup v2 does not yet support real-time processes. If we need to deploy some real-time processes on the system, they should be placed on the root cgroup.
Let me introduce our case.
We run bird and chrony on each worker node as real-time processes since they require small latency to function normally.
We made systemd services that start them as Docker containers and then write ExecStartPost instructions to move them to the root cgroup.
The following is an excerpt from our code.
You can see the complete service definition on our repository.
The service waits for Docker to publish the process ID, writes it to cgroup.procs of the root cgroup, then makes the bird a real-time process using the chrt command.
ExecStart=/usr/bin/docker run --name bird ... ExecStartPost=/bin/sh -c 'while ! docker container inspect bird >/dev/null; do sleep 1; done' ExecStartPost=/bin/sh -c 'echo $(docker inspect bird | jq ".[0].State.Pid") > /sys/fs/cgroup/cgroup.procs' ExecStartPost=/bin/sh -c 'chrt --pid --rr 50 $(docker inspect bird | jq ".[0].State.Pid")'
Two things to prepare for workloads
Two things can optimize application performance on cgroup v2 systems.
Go
When we want to limit the available CPU time (the quota) for a container, we set resources.limits.cpu in the container specification in the Pod manifest.
The complicated part is that the cgroup grants a certain amount of CPU time for processes in a container to consume within a fixed time frame.
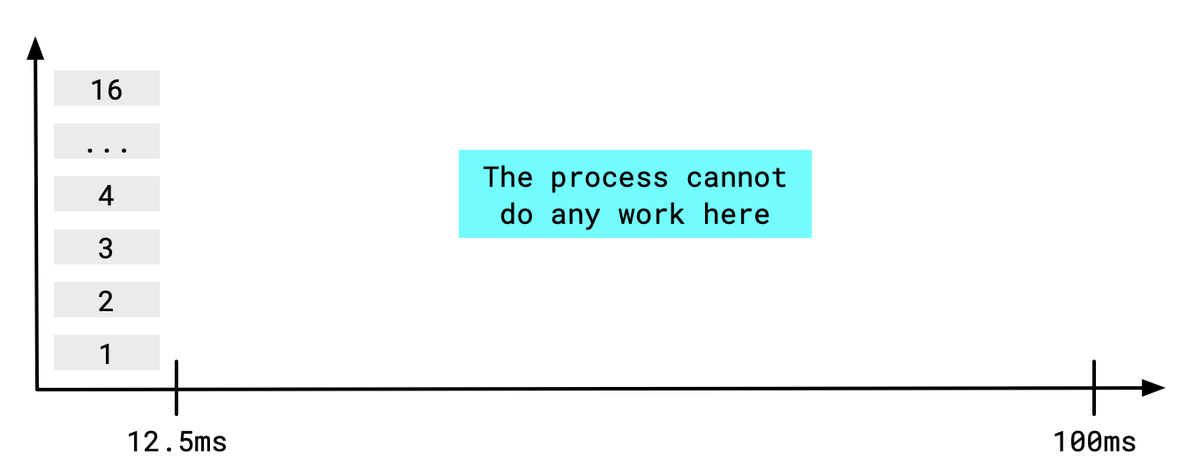
The time frame is typically 100ms.
What happens?
If we set resources.limits.cpu as 2000m, it allows the container twice the CPU power of a single core.
It means the container may use 200ms of CPU time within a 100ms time frame.
Surprisingly, if a process in the container runs 16 threads (it should have decided to do so because the machine has 16 cores), it runs out of the quota within 12.5ms!
The processes in the container can't do any work in the remaining 87.5ms and may drop health check requests arriving during the freezing winter.
Of course, we need to tell the process to utilize two threads.
There is a good post on this topic, so I recommend reading it through.
The actual way to set the number of threads is language-specific.
For Go programs, set the GOMAXPROCS environment variable to an appropriate number.
uber-go/automaxprocs is a well-known tool that reads the CPU quota from the cgroup interface and automatically sets the environment variable.
If you're using a version until v1.4.0, you need to patch it with a cgroup v2 PR or set GOMAXPROCS manually for a while.
Java
We need to use JDK 15 or later to run Java applications properly in the cgroup v2 environment. Let me describe it briefly.
JDK has built-in support for the container environment from version 8u131.
JDK 10 introduced the +UseContainerSupport option and enabled it by default.
With this option, JDK inspects the cgroup filesystem and reads the CPU and memory quotas for its use.
The CPU quota information is available on Runtime.availableProcessors() (see Docker blog for details).
The memory quota affects its heap memory usage.
This mechanism should be adjusted for cgroup v2, and the fix became available with JDK 15.
Conclusion
This blog post described five things to adopt for cgroup v2 with Kubernetes. Since there are some caveats to adopting cgroup v2 at the time of writing, we recommend not to rush into it until the ecosystem matures a bit further. This situation may change at the time of reading.
References
The following documents and lectures are beneficial for learning how cgroup v2 works.
Control Group v2
https://www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.htmlControl Group APIs and Delegation
https://systemd.io/CGROUP_DELEGATION/An introduction to control groups (cgroups) version 2
https://www.youtube.com/watch?v=kcnFQgg9ToYDiving deeper into control groups (cgroups) v2
https://www.youtube.com/watch?v=Clr_MQwaJtARoboto Mono Font (used in figures, licensed under the Apache License, Version 2.0).
https://fonts.google.com/specimen/Roboto+Mono